Введение
На выходных сектор ИИ вновь был взбудоражен анонсами от DeepSeek. Речь идет не просто об очередном улучшении инструмента для распознавания текста, а о прорывной технологии, которую можно назвать контекстным оптическим сжатием. Этот подход использует визуальные методы для решения фундаментальной проблемы обработки сверхдлинных текстовых массивов, предлагая новый вектор работы с огромными данными.

Любой, кто активно использует большие языковые модели (LLM), сталкивался с ограничением контекстного окна:
- *При запросе на суммирование десятков тысяч слов из стенограмм конференций или научных отчетов, производительность модели деградирует, происходит "потеря памяти".**
Это прямое следствие квадратичной сложности длины последовательности, которая ограничивает такие модели, как GPT, Gemini и Claude. Увеличение входных данных экспоненциально повышает требуемые вычислительные ресурсы. Человеческое восприятие работает иначе: мы можем мельком взглянуть на диаграмму или заметку и мгновенно восстановить обширный контекст.
Традиционно, чтобы LLM могла обработать длинный документ, весь контент должен быть преобразован в цифровой текст. Этот процесс чрезвычайно токеноемкий (токены — это базовые единицы, используемые ИИ для обработки информации), что влечет за собой низкую вычислительную эффективность.
Революция в Обработке Данных: Визуальное Сжатие от DeepSeek
DeepSeek-OCR предлагает альтернативный механизм. Сначала он конвертирует текст в изображения, а затем применяет визуальные токены для эффективного сжатия этой информации. Представьте статью объемом 10 000 слов: вместо того чтобы заставлять модель читать ее последовательно, DeepSeek-OCR позволяет ей "взглянуть" на сжатое изображение для понимания и реконструкции исходного текста.
Ключевой прорыв заключается в способности представлять богатую информацию документа в одном изображении, используя на порядок меньше токенов, чем эквивалентный текстовый формат. Это подразумевает, что оптическое сжатие через визуальные токены достигает более высоких коэффициентов сжатия, позволяя выполнять больше задач с меньшими затратами ресурсов.
Демонстрация Агентной Системы
Чтобы проиллюстрировать это, рассмотрим работу чат-бота, построенного на этой архитектуре. При запросе типа: *«Каковы основные выводы?»* агент выполняет следующую логику:
1. Он извлекает текст с каждой страницы документа.
2. Если страница содержит менее 50 символов или не имеет извлекаемого текста, страница преобразуется в изображение высокого разрешения и отправляется в DeepSeek-OCR через Replicate API.
3. DeepSeek-OCR использует подход "Контекстного оптического сжатия", преобразуя документ в визуальные токены, тем самым сжимая информацию. Это позволяет модели "видеть" изображение, а не читать текст слово за словом, эффективно трансформируя 10 000 слов в высокосжатый формат.
После извлечения всего текста система приступает к индексации для RAG:
- Текст разбивается на фрагменты размером 500 символов с перекрытием в 50 символов для сохранения контекста.
- Каждый фрагмент векторизуется с использованием эмбеддингов
OpenAI. - Векторы сохраняются в векторной базе данных
Chroma, которая персистентно хранится на диске для последующего использования.
При получении запроса, агент ищет 5 наиболее семантически схожих фрагментов в векторном хранилище. Эти фрагменты, вместе с исходным вопросом пользователя и инструкциями по цитированию номеров страниц, формируют контекстный промпт. Этот промпт затем отправляется модели Llama 3.1 405B, работающей через потоковый API Replicate. Модель генерирует интеллектуальный ответ поэтапно в реальном времени.
В итоге, ответ сопровождается цитатами из исходного документа с указанием номеров страниц, что создает полноценного RAG-агента, способного семантически обрабатывать любые PDF-файлы.
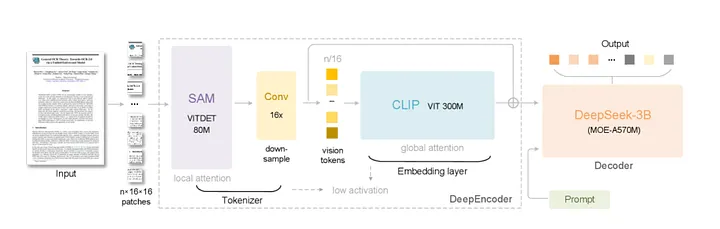
Архитектура DeepSeek-OCR: От Изображения к Токенам
DeepSeek-OCR позиционируется как сквозная модель для OCR и парсинга документов, нацеленная на достижение оптического контекстного сжатия.
Его архитектура состоит из двух ключевых компонентов:
DeepEncoder: Отвечает за сжатие входного изображения высокого разрешения в минимальное количество визуальных токенов.DeepSeek-3B-MoE(языковая модельMixture-of-Experts): Декодер, который восстанавливает исходный текст из полученной последовательности визуальных токенов.
Детали Кодирования и Декодирования
DeepEncoder (около 380 миллионов параметров) использует механизм оконного внимания на основе SAM для выделения локальных признаков изображения. Встраивание двухслойной CNN с 16-кратным сжатием позволяет ему эффективно уменьшить изображение размером 1024x1024 пикселей (исходно 4096 патчей) до приблизительно 256 токенов.
Декодер, получающий эти визуальные токены, имеет общую мощность в 3 миллиарда параметров (около 570 миллионов активных во время инференса). Используя структуру MoE, он динамически выбирает 6 экспертов из 64 доступных на каждом шаге, обеспечивая легковесную, но точную реконструкцию текста.
Благодаря этой гибридной архитектуре, DeepSeek-OCR использует нетрадиционный путь: преобразование содержимого документа в изображение, а затем его "чтение".
Сравнение Производительности: DeepSeek-OCR против PaddleOCR-VL
При тестировании различных OCR моделей было обнаружено интересное различие. PaddleOCR-VL, модель с меньшим количеством параметров (0,9 млрд), в реальных сценариях показала превосходство над более крупной моделью DeepSeek-OCR (3 млрд параметров).
Сложные задачи включали:
- Корректное чтение вертикального текста.
- Интерпретацию сложных математических формул.
- Обработку многоколоночных документов.
PaddleOCR-VL блестяще справилась со всеми этими тестами, в то время как DeepSeek-OCR допускала ошибки в порядке чтения и распознавании формул, несмотря на заявленные функции сжатия.
Дальнейшее изучение исследовательской статьи DeepSeek-OCR выявило, что разработчики выразили благодарность PaddleOCR за использование ее для разметки обучающих данных. Это наводит на мысль: компании вроде Baidu, DeepSeek и Shanghai AI Lab выпускают OCR-модели не как конечный продукт, а как побочный эффект очистки огромных датасетов для обучения их основных ИИ-моделей, а мы получаем эти мощные OCR-инструменты в качестве бонуса.
В итоге, для задач, требующих высокой точности при чтении печатного текста, форм, таблиц или многоязычных документов в реальных рабочих процессах, PaddleOCR-VL является предпочтительным выбором. DeepSeek-OCR, напротив, будет более выгоден исследователям, стремящимся минимизировать затраты на ИИ за счет агрессивного сжатия данных.
Анализ Токенов: Текстовые против Визуальных
В стандартных LLM текст сегментируется на дискретные текстовые токены (обычно слова или субслова). Каждому токену присваивается фиксированный идентификатор из словаря, и он отображается в вектор через слой эмбеддинга. Этот метод эффективен, но ограничен размером словаря.
Визуальные токены работают совершенно иначе:
- Они являются непрерывными векторами, генерируемыми непосредственно из пикселей изображения с помощью визуального энкодера, а не извлекаются из фиксированной таблицы поиска.
- Более высокая плотность информации: Будучи непрерывными векторами, они могут кодировать более богатые и детальные данные, включая цвет, форму, текстуру и пространственные отношения внутри области, а не просто лексему.
- Глобальное восприятие паттернов: Визуальный энкодер способен улавливать глобальные характеристики макета, верстки и стиля шрифта, которые теряются при последовательной обработке простого текста.
- Расширенное пространство выражения: Теоретически, словарь визуальных токенов бесконечен, поскольку они являются непрерывными векторами, генерируемыми динамически, а не выбираемыми из предопределенного набора.
Практическая Реализация Агентного OCR-RAG
Для демонстрации возможностей, мы настроим идеальную среду для разработки, начиная с установки необходимых библиотек Python.
# Установка зависимостей
pip install ...Следующий этап — импорт критически важных библиотек и базовая конфигурация системы.
# Импорт библиотек и настройка
import os
from langchain_core.documents import Document
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
# ... (другие импорты)
# Конфигурация API и параметров
API_KEY = os.getenv("REPLICATE_API_TOKEN")
LLM_MODEL_ID = "meta/llama-3.1-405b:..."
EMBEDDING_MODEL = "text-embedding-3-large"Разработка Пользовательской Модели LLM
Я разработал кастомный класс Llama, который наследуется от базового класса LLM в LangChain. Он настроен для работы с идентификатором модели Llama 3.1 405B, включая лимиты токенов и температурные настройки.
Обязательное свойство llmtype возвращает идентификатор модели. Основной метод _call принимает промпт, упаковывает его с конфигурацией в словарь и отправляет в потоковый API Replicate, итерируя по фрагментам ответа для сборки финального результата.
from langchain_core.language_models.llms import LLM
class Llama(LLM):
# ... реализация класса Llama
def _call(self, prompt: str, stop: list[str] | None = None) -> str:
# ... логика потоковой отправки в Replicate API
pass
@property
def _llm_type(self) -> str:
return "llama_custom"Создание Интеллектуального Загрузчика OCRPDFLoader
Я создал класс OCRPDFLoader для надежного извлечения текста из PDF. Он приоритизирует прямое извлечение текста, переключаясь на OCR только при необходимости.
Инициализация включает путь к файлу, опциональный флаг ocr_enabled и пороговое значение текста (по умолчанию 50 символов) для определения, достаточно ли текста на странице.
Метод load открывает PDF через PyMuPDF, итерирует по страницам для извлечения текста. Если OCR включен или извлеченный текст не превышает порога, вызывается метод ocrpage:
ocrpageпреобразует страницу вPNG-изображение высокого разрешения.- Изображение отправляется в
DeepSeek-OCRчерезReplicate API. - Полученный текст
OCRвозвращается, временное изображение удаляется.
Наконец, текст каждой страницы оборачивается в объекты Document LangChain с метаданными (исходный файл, номер страницы), создавая "умный загрузчик", который прозрачно обрабатывает как цифровые, так и сканированные PDF.
from fitz import open as open_pdf
from PIL import Image
class OCRPDFLoader:
# ... реализация класса OCRPDFLoader
def load(self):
# ... логика открытия PDF, итерации по страницам
if ocr_needed:
ocr_text = self._ocr_page(page)
# ... упаковка в Document
return documents