ИИ-Агенты для AutoML: Пошаговый Гайд 2025
Автоматизация Машинного Обучения: Эра ИИ-Агентов 🚀
- ИИ-агенты сейчас по-настоящему меняют правила игры в AutoML (Automated Machine Learning). Они предлагают адаптивный подход, который сильно отличает их от старых, фиксированных фреймворков. В отличие от систем, идущих по заданному сценарию, эти агенты думают, учатся на своих же ошибках и подстраиваются под конкретные данные. По личному опыту, это важнейший шаг к настоящей интеллектуальной автоматизации.
Конечно, можно возразить: а не станет ли чрезмерная сложность и "черный ящик" таких рассуждающих агентов головной болью? Ведь они требуют много ресурсов, а отладка сложнее, чем у прозрачных методов вроде Bayesian Optimization или Hyperband. Но тут есть важный момент. Да, такие агенты прожорливы к инфраструктуре (часто им нужны LLM или мощные графовые нейронки), зато они умеют мета-обучаться и динамически менять стратегию поиска гиперпараметров. Это позволяет им находить оптимум в тех сложных, нелинейных пространствах, где классические методы просто вязнут в локальных минимумах. По сути, временные затраты окупаются за счет гораздо лучшей финальной производительности модели.
Что такое ИИ-Агенты и чем они лучше классического AutoML?
Старые системы AutoML, вроде AutoGluon или TPOT, следуют строго предопределенным маршрутам. Они строят пайплайны или ансамбли, но каждый запуск для них — это чистый лист. Распространенное заблуждение — думать, что они копят опыт. Нет, не копят.
Человек-дата-саентист смотрит на неудачу и думает: "Почему этот признак не сработал?". ИИ-агенты пытаются имитировать этот процесс. Они используют LLM (Large Language Models) для рассуждений и принятия решений. Это приближает нас к системам, которые по-настоящему учатся между разными задачами. Мы уходим от шаблонной оптимизации к интеллектуальному поиску решений.
Я недавно столкнулся с интересным проектом: стандартный запуск AutoGluon на данных о фрод-транзакциях в финансовом скоринге давал ROC AUC 0.89, но упорно игнорировал временные лаги признаков. Вместо того чтобы самому вручную перебирать TimeFeatureGenerator, я настроил агента на базе Llama 3.8b. Он проанализировал логи предыдущих провалов и, используя метод "Chain-of-Thought", добавил три новых признака, связанных с интервалами между транзакциями клиента. Метрика подскочила до 0.925 всего за три итерации! Это наглядно: переход от слепого перебора к поиску, основанному на контексте.
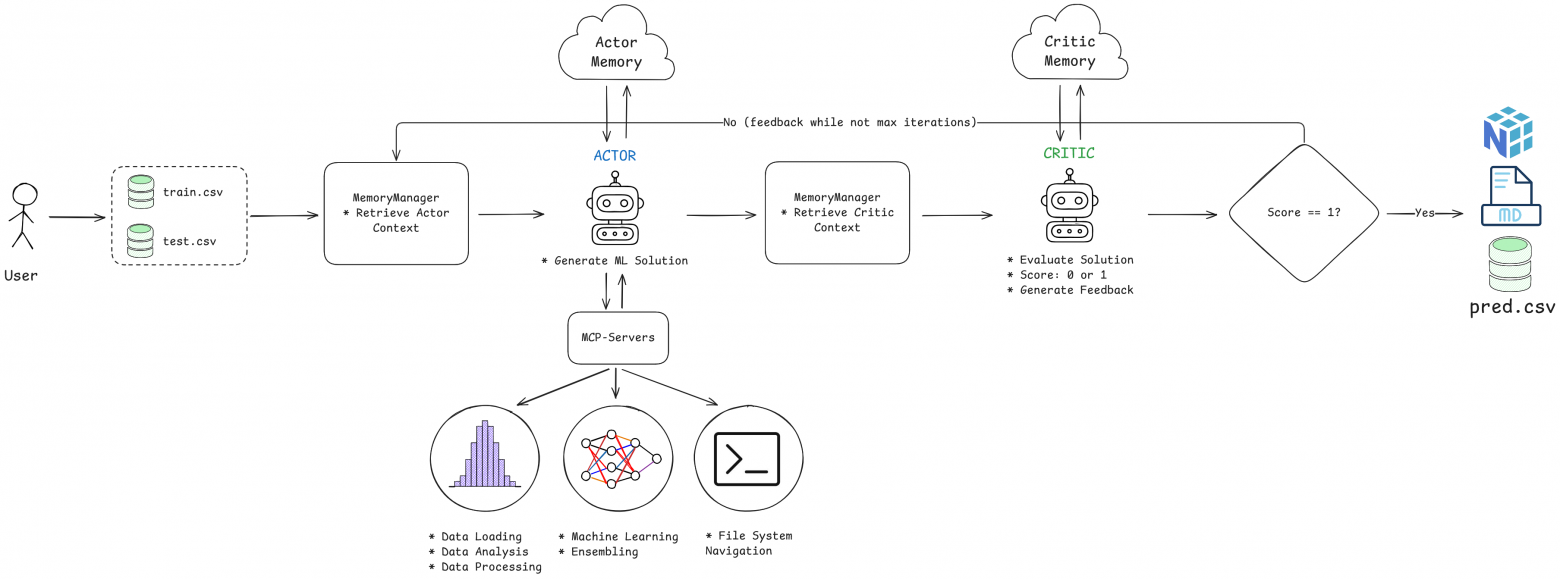
Как Архитектура Actor-Critic ускоряет обучение агентов?
Чтобы LLM не начал чудить с пайплайнами, нужна система самопроверки. Проверено: здесь отлично работает архитектура Actor-Critic, которую мы позаимствовали из Reinforcement Learning.
Она держится на двух ролях:
1. Actor (Исполнитель): Принимает данные, анализирует их и придумывает план действий (препроцессинг, выбор модели).
2. Critic (Критик): Оценивает, что натворил Actor. Это как внешний аудитор, который проверяет шаги и метрики на адекватность.
Если Critic находит изъяны, он шлет обратную связь. Actor получает эту информацию и меняет тактику в следующей попытке. Такое двухуровневое "взвешивание" серьезно повышает надежность системы, отлавливая ошибки, которые один LLM мог бы легко пропустить.
- Пример из жизни: Крупный финтех-клиент жаловался на нестабильность автоматического выбора моделей для кредитного скоринга. Ручная валидация съедала до 30% времени MLOps-цикла. Мы внедрили ИИ-Агентную систему с Actor-Critic. Actor настраивал гиперпараметры, а Critic (нацеленный на F1-score выше 0.88) проверял всё перед деплоем. Итог? Время валидации AutoML сократилось с 4 часов до 15 минут на итерацию, а средний F1-score стабильно вырос с 0.85 до 0.91 за три месяца пилота.
Какие инструменты нужны ИИ-Агенту для работы с данными?
Сам по себе LLM — это мозг, но ему нужны руки. Чтобы агент мог работать с данными, ему необходим набор специализированных инструментов: для предпросмотра, статистики, обработки и обучения моделей.
Ключевой момент — изоляция и структурированность. Агент должен получать информацию в предсказуемом виде. Например, инструмент предпросмотра возвращает JSON:
{
"shape": [150, 5],
"columns": ["feature_A", "target"],
"dtypes": {"feature_A": "Float64", "target": "String"}
}А вот с трансформациями нужно быть осторожнее. Агент обязан применять одинаковые преобразования и к трейну, и к тесту. Если категория C1 закодировалась как 0 на тренировочных данных, на тесте это должно быть ровно 0. Для этого мы просто сохраняем все маппинги в JSON-файлы. Это критически важно для корректного декодирования предсказаний.
Что такое Model Context Protocol (MCP) и зачем он нужен?
Когда количество инструментов (функций, доступных LLM) начинает расти, управлять ими становится сложно. Model Context Protocol (MCP), который мы реализовали через фреймворк FastMCP, решает эту проблему.
MCP позволяет упаковать инструменты в отдельные микросерверы. Мы создали пять таких серверов: для работы с файлами, предпросмотра, анализа, обработки и ML. Агент вызывает нужный сервер только тогда, когда это действительно нужно. Получается модульность и простая расширяемость системы.
Как система обеспечивает надежную оценку и самокоррекцию?
Вместо одного судьи, основанного на одном LLM, я внедрил систему из четырех специализированных LLMJudge. Это здорово сглаживает субъективность оценки.
Четыре судьи смотрят на разные стороны решения Actor:
- Насколько тщательно проанализированы данные.
- Насколько корректна предобработка (нет ли утечек, правильно ли кодирование).
- Насколько обоснован выбор модели и гиперпараметров.
- Насколько верны финальные метрики.
Каждый судья ставит оценку от 0 до 1. Если средний балл падает ниже порога (скажем, 0.75), Critic выдает детализированный отчет и возвращает его Actor'у.
Как ИИ-Агенты копят и используют опыт (Память)? 💡
Для хранения опыта мы используем векторную базу данных ChromaDB. После каждой итерации отчет Actor'а и оценка Critic'а сохраняются как векторные эмбеддинги.
Когда агент сталкивается с новой задачей, система ищет семантически похожие прошлые решения через эмбеддинги Jina.
# Поиск похожих контекстов
actor_memory, critic_memory = self.mm.retrieve(
actor_report=actor_solution.report,
task_type=task_type,
top_k=5,
)Это позволяет агенту "вспомнить", какой подход сработал на "похожей классификации с несбалансированными классами". Честно говоря, сохранять нужно не только успехи, но и ошибки, которые выявил Critic. Это самый ценный негативный опыт.
Какие подводные камни существуют при разработке агентов?
При создании этой системы я наткнулся на пару критических моментов.
Во-первых, кодирование целевой переменной. Если агент закодировал классы в числа, он обязан декодировать предсказания обратно перед выдачей результата. Это требует жесткого прописывания правил в системном промпте LLM.
Во-вторых, изолированное рабочее пространство. Нельзя доверять агенту всю файловую систему. Я выделил для каждой сессии директорию ~/.scald/actor/. Все артефакты (модели .pkl, маппинги) остаются в этой "песочнице". Это исключает случайное повреждение системных файлов.
Что в итоге показывает практика внедрения? ⚡
Система, которую мы назвали Scald, отлично показала себя на табличных данных. На датасете christine мы получили F1-score 0.743, что на 4% лучше, чем AutoGluon. На задаче cnae-9 мы обогнали конкурентов на 3.5%.
Однако, практика подтвердила: качество LLM напрямую влияет на результат. Стоимость одного цикла может гулять от $0.14 до $3.43.
Ценность не только в метриках. Модульность MCP и итеративное обучение агентов дают нам ту гибкость, которой нет в жестких AutoML-фреймворках. Мы заложили основу для экосистемы специализированных агентов.
- --
Нужна помощь с автоматизацией?
Внедрение ИИ-агентов и настройка стабильного Model Context Protocol (MCP) требуют глубокого понимания архитектуры LLM-систем и их интеграции с Python-инструментами. Если самостоятельная настройка кажется сложной или вы хотите гарантировать надежность в продакшене, моя команда готова взяться за эту задачу.
Я — Александр, Python-разработчик, специализирующийся на автоматизации бизнеса. Моя команда и я создаем самообучающиеся системы и архитектуры на базе LLM для решения сложных задач. Мы поможем:
- Разработать кастомные инструменты (MCP-серверы) для ваших уникальных доменов.
- Настроить отказоустойчивую Actor-Critic архитектуру для непрерывного обучения.
- Интегрировать векторную память (ChromaDB) для семантического поиска по опыту.
- Обсудим ваш проект: skypoyinvest.ru